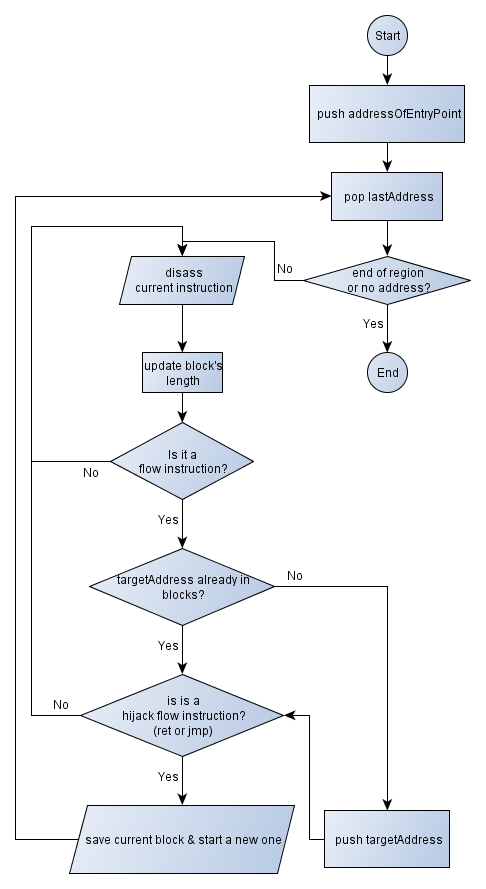
This article follows next to the Thougts about disassembling algorithms one. If you haven't read it yet then I strongly suggest you to do so, otherwise you wouldn't find any interest in the following lines.
After having gathered tips and tricks about the guidelines of the algorithms, one another interesting approach would be thinking about a modular software architecture that could properly encapsulate our algorithms, thus preparing the field for further features as:
- disassembling other instruction sets;
- interchanging mnemonics syntaxes;
- embedding the algorithms into pieces of software;
- and so on...
But let's not fall into an unterminable and boring speech and instead let's dig into our architecture.
Abstract representation of instructions
May I recall you that I came up with four kinds of instructions, which respectively are normal, referencing, flow and hijackflow.First and foremost, we must think about one point: what do these types have in common? One obvious property that I came up with is the total size. By saying this, I mean the size of the eventual prefix plus the size of the opcode(s) plus the size of the operands. In a nutshell, it is the size of the stream of bytes we disassembled to build one single instruction.
A referencing instruction is an instruction that, once having been decoded, appears to deal with any memory address. It can either fetch data stored at this address or jump to it; there's actually many possibilities. Just keep in mind that it has a memory address to do something with.
Starting from this statement, therefore we may establish that both flow instruction's type and hijacking flow instruction's type are referencing instructions as well.
Last but not least, it is obvious to say that an hijacking flow instruction is a flow instruction, in addition of hijacking the execution flow (unconditional jump, ret, etc.).
We have a kind of beautiful inheritance so far. HijackFlowInstruction IS A FlowInstruction, FlowInstruction IS A ReferencingInstruction, and ReferencingInstruction IS AN Instruction.
The figure 1 sum things up with an UML diagram, showing the inheritance of the classes.
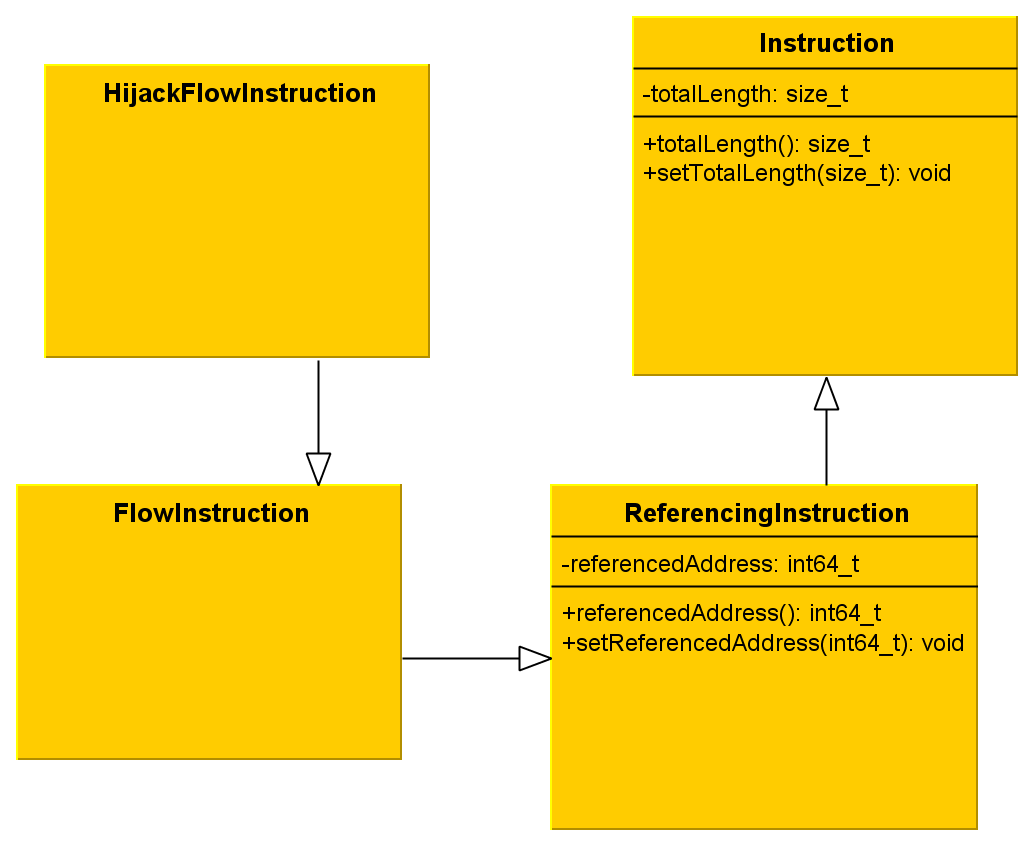
Figure 1 - Inheritance among the instruction types
Binary Blocks: showing the way we rule
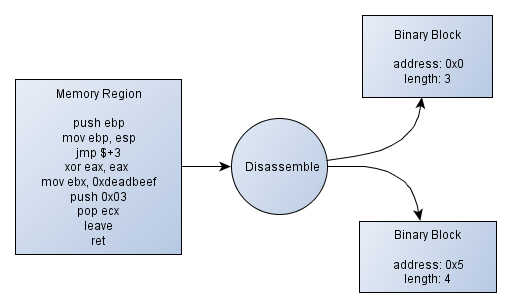
Do you remember the Figure 2 of the previous article? It showed what we want to do with a binary region.A binary block is made of a reference address and the size it covers. We won't hold the content since we don't need it, moreover it would cost a lot of memory.
As we do want to distinguish code from data (how many times shall I repeat it?!) we can assume we have at least two respective kinds of blocs:
- Code blocks: these blocks will handle binary code that is meant to be disassembled with the linear sweep algorithm;
- Data blocks: these blocks will handle data.
Another probable issue regarding the code blocks would be the following one: assume you are disassembling instructions in a sequential way, registering referenced memory addresses that are likely to contain code. What if the reference address we've just computed points into an existing block? We won't disassemble the same code twice, but the instruction needs to reference another one with a label once we've procuded the final listing (I mean the source code). So we have to hold this address into the current code block. As a consequence, we will state that a code block as a list of symbols, which consists of the referenced instructions into the blocks.
Firstly, it avoids splitting a block, what could be a cumbersome operation; secondly, if the memory address points into the middle of a single instruction, then it would be considered as an invalid symbol and therefore it would result in a raw binary address in the listing, assuming that we don't know how to handle it, but we would still have a source code that produces exactly the same binary stream we've disassembled so far.
Let's focus on the data blocks now: there are many data sizes that we know, even more since we are low-level programmer. 1 byte (BYTE), 2 bytes (WORD), 4 bytes (DWORD), 8 bytes (QWORD).
For example, one would find it interesting that it could represent a DWORD instead of a stream of bytes, most especially if the piece of data is actually a binary address according to the context, etc. Therefore, sometimes, one line of:
DD 0xdeadbeef ; DD stands for Declare Double word
Would be more suitable than:
DB 0xef, 0xbe, 0xad, 0xde ; DB stands for Declare Byte
Thus our data block must handle the granularity of the data type it contains. Even though we won't especially end up with data blocks containing multiple words or dwords since we only deal with static memory addresses and don't perform symbolic execution, printing data into word or dword format would be interesting, especially if we encode, for example, a binary header into our assembly listing!
So does a data block needs to have a size attribute when it states that the pointed data is at least a word? At a first glance the answer is no, but I decided else and I will explain why.
Suppose you've previously reverse engineered the binary you want to disassemble. By any luck, you have identified valuable information that our algorithm couldn't have because it does not perform any single symbolic execution. For example, you may have spotted a callback that is dynamically computed, or a function pointers table somewhere into the memory.
One could enjoy providing the algorithms with information he has found. Actually it's already the case: you provide the entry point, but what if you could provide other information like "there's code at this address, and exactly 8 QWORDS at that address"? This could help ending up with a listing as clear as possible.
That is why we will hold the size into a word-block or a dword-block. The figure 2 shows a tiny UML diagram that summarizes what I tried to explain:
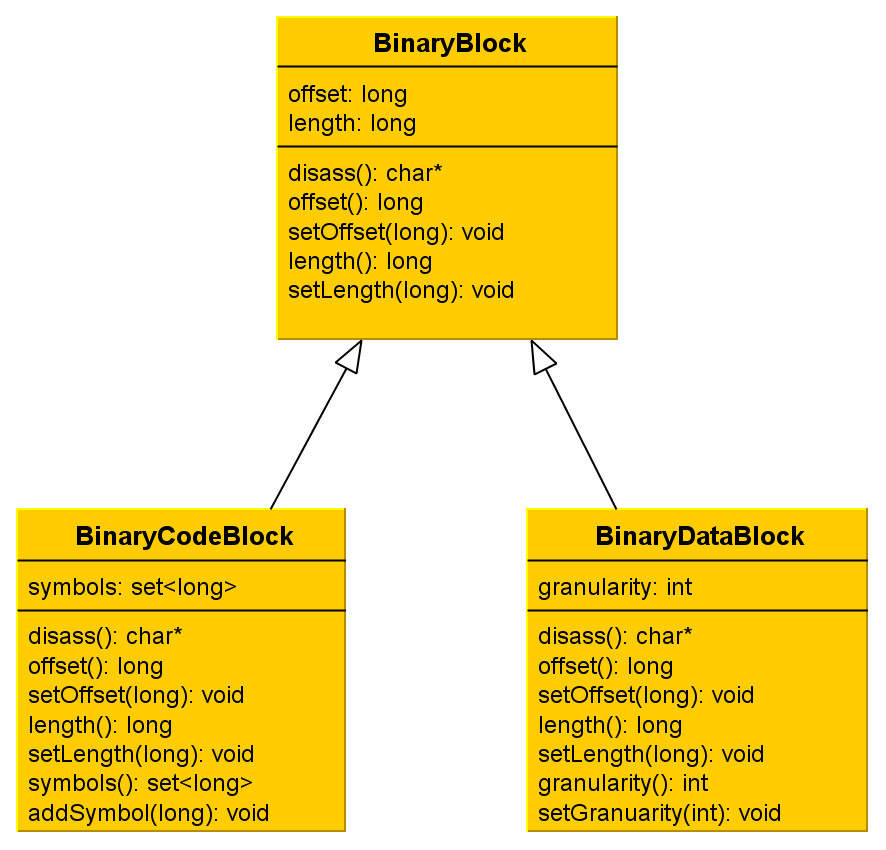
Figure 2 - Two types of blocks to handle a binary region
You may notice there's a disass() method among the three classes and I should have told you about this sooner. It is a temporary solution to disassemble a binary block since we don't disassemble a code block the same way as we do for a data block. The polymorphism magic shall operate at this point, unless I eventually find out it does not fit to a flexible architecture. Maybe the Visitor pattern shall be applied in order to separate what can be changed (algorithms) from what should not be. We'll see later.
By navigating through every single binary block that has been produced by the algorithm as well as by the user, a binary region can easily be disassembled to produce accurate results.
What's next?
I'll try to keep releasing small articles like the first ones. I am currently thinking on releasing source code as well (still nothing, damn!) with a concrete experimentation on x86 by using the libdasm project. I also checked the libasm project out - which is part of the ERESI one. Choosing the most suitable library takes a bit of time and I will try to figure this out as quickly as possible.
So, next time, I'll try to show concrete stuff out, like disassembling a x86 binary region and producing a listing. If not, then you'd be at least given some examples of what I want to do (examples of inputs and outputs) in order to understand evermore the purpose of my project.
Thanks for having read this article, feel free to drop some feedback, regardless of it's english mistakes or if you have a better sight of my non mature software architecture. :)
Ge0